Your AI Data Stays Private by Default
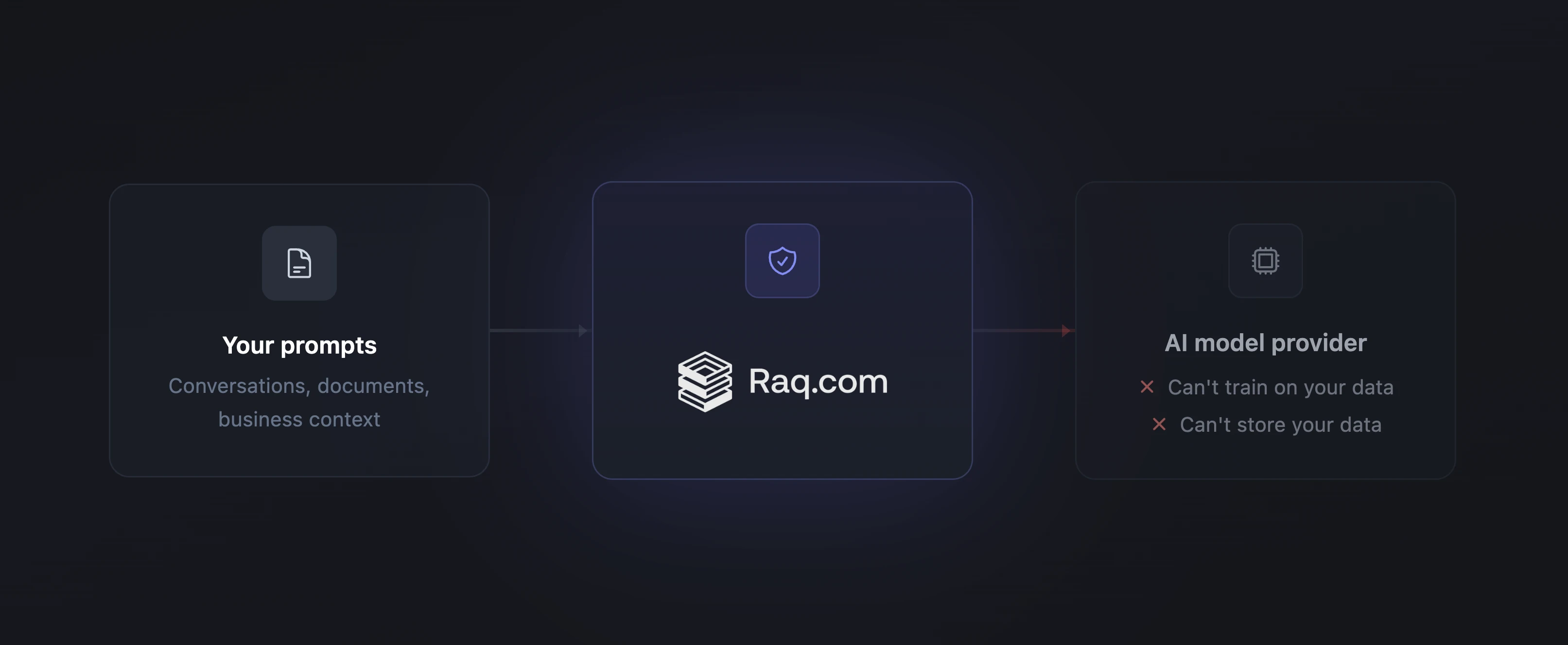
Most AI services train on your data by default. Your conversations, your prompts, your business context, all feeding the next model update. On Raq.com, that is blocked by default for core text AI work, with live web search handled as a separate, explicit exception.
The default is the problem
ChatGPT, Gemini, Meta AI: all train on your data unless you find the opt-out. The opt-outs exist, but they are buried in settings that change without notice. For business data or compliance-sensitive content, that is a risk you should not have to manage.
Training and retention are different risks
Most privacy conversations focus on whether a provider will use your inputs to improve their models. But retention matters just as much. Even when a provider promises not to train on your data, they might still store your prompts for weeks or months.
How zero data retention works
For text-based AI (chat, rewriting, document analysis), Raq.com routes requests through provider endpoints that enforce zero data retention (ZDR). This is a technical constraint applied on every request, not a policy you have to trust. The protection does not depend on a provider's terms of service. It is built into how the request is processed.
Every new account starts with ZDR enabled. You do not have to remember to turn it on.
Live web search is the exception
If you ask for current headlines, breaking news, or anything that requires a real web lookup, Raq.com can use live web search. That setting is controlled separately in AI Privacy and is on by default so current-information requests work without friction.
When live web search is enabled, those lookup requests may use standard provider routing rather than ZDR. That exception applies only to the search step itself. Core text and chat AI requests still follow your main AI privacy setting.
Want access to more models?
Some models are only available from providers that have not committed to zero data retention. You can disable ZDR in your account's AI Privacy settings to access them. The same settings page also lets you disable live web search entirely if you do not want search lookups to leave privacy-protected routing. It shows exactly which models are available with protection on and which become available when you turn it off.
Image, video, and voice
Image, video, voice, and transcription requests are processed by specialist providers. We have opted out of model training where providers offer the option. All generated content is downloaded to Raq.com's own secure storage immediately after creation. Only the inputs necessary for each operation are sent.
What Raq.com itself stores
Raq.com maintains its own request logs for billing, service quality, and debugging. We do not use your data to train AI models. Full details are in our Privacy Policy.
The bottom line
If you are using AI for anything beyond casual queries, you should know where your data goes. On Raq.com, core text AI data does not go to model training or provider storage by default. Live web search is separately controlled because current-information lookups need a different path. All generated content is stored on our own infrastructure. For full details, visit the Privacy and Security page.